Can AI code? Only in small steps!

The first days of the public availability of ChatGPT by OpenAI last winter provided proof of the program’s ability to generate computer code. Which was a revelation for the developers. It seemed from the outset that ChatGPT was so good at code that, suddenly, even people with little coding knowledge could use it to generate powerful software.
Many months of experience and research on the subject have revealed that ChatGPT and other generative ais cannot actually develop programs as such. The best they can do is to propose small steps, for simple coding problems.
“What generative AI has shown is that I can have a partner when I perform a task, who gives me suggestions and who allows me to overcome creative obstacles,” said Naveen Rao, co-founder and CEO of the AI startup MosaicML, which was acquired in August by Databricks.
“Ais don’t even write particularly good code. This is beginner code.”
But this level of assistance for IT development is low.
“It gives you a kind of scaffolding, with some things that can be repeated, but that’s it,” he said. “If I ask to solve a very difficult problem, it is not possible. Ais don’t even write particularly good code. This is beginner code.”
Some studies show that large language models such as GPT-4 are much inferior to those of human coders in terms of the overall quality of the code.
Developers above GPT-4
A recent study carried out by Sayed Erfan Arefin and his colleagues from Texas Tech University tested GPT-4 and its predecessor, GPT-3.5, with coding problems taken from the online platform LeetCode. It is these types of problems that are posed to candidates at Google, for example.
The programs were evaluated on the basis of two tests: “organizing the data for efficient access (using appropriate data structures)” and “creating workflows to process the data (using efficient algorithms)”. They were also evaluated on the so-called “string manipulation”, which overlaps with the other two challenges.
When the language models were subjected to what the authors call “complete questions”, that is, the programs were given examples of solutions to the questions, GPT-4 answered only 26% of the questions correctly, compared to 45% for human respondents.
When some information was deleted, the capacity of GPT-4 dropped to 19% of the questions answered correctly. GPT-3.5 is located around 12% and 10%, respectively.
The authors also examined the quality of the GPT code, both for successes and failures. In both cases, they noticed a problem: GPT often had difficulties with a basic coding practice, namely “defining variables consistently”.
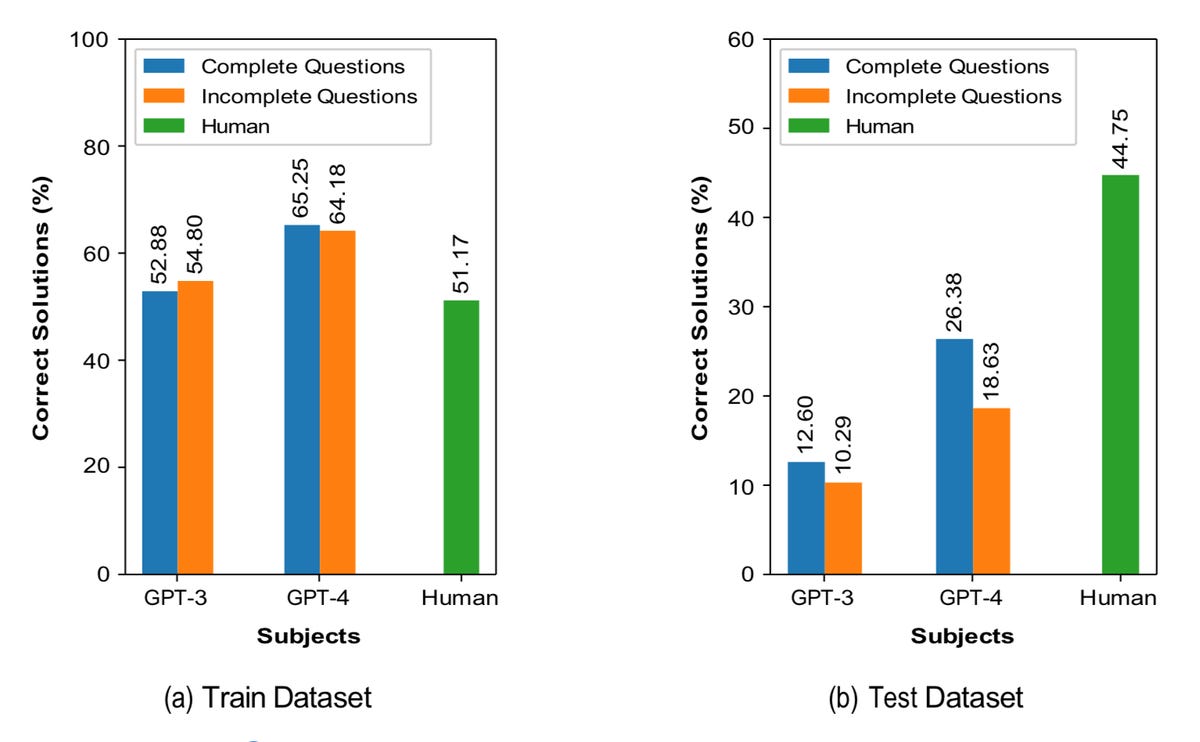
Correction of GPT-3, GPT-4, and humans, for training and test sets, when they are given either complete information about the problem, with examples of solutions, or incomplete information. Texas Tech University
Moving from basic problems to complex programming problems
Scaling is also a problem for the generation of codes by an AI. The most encouraging results obtained so far by GPT-4 in terms of code generation relate only to childish problems.
One study, carried out by David Noever from the cybersecurity company PeopleTec, tested GPT-4’s ability to find faulty codes in code samples. This is a job that is usually done by vulnerability testing programs, such as Snyk, or SAST.
In some cases, GPT-4 found more errors than Snyk, the authors said. But he also went through many mistakes. Above all, GPT-4 has been tested on just over 2,000 lines of code. A tiny figure compared to applications that can contain hundreds of thousands, or even millions of lines of code, distributed in many linked files.
It is therefore not certain that the successes achieved by AI on childish problems can extend to such complexity.
AI evaluates variables incorrectly
A study carried out last month by Zhijie Liu and his colleagues from ShanghaiTech University examined the quality of the code in terms of its accuracy, comprehensibility and security. The study also tested ChatGPT on LeetCode tasks. And they also tested its code generation on what is called the Common Weakness Environment, a vulnerability test maintained by the MITRE research company.
They tested ChatGPT on tasks formulated before or after 2021, because ChatGPT was only trained on pre-2021 hardware, and therefore they wanted to see how the program behaves on both old problems and newer problems.
And the results are striking. For the most recent problems, called “Aft.”, for “after” 2021, He and his team have found very low correction rates. “ChatGPT’s ability to generate functionally correct code decreases significantly as the difficulty of the problem increases,” they write. Only 15.4% of the program code in the C language was acceptable, and none was acceptable for the most difficult problems. In addition, “the code generated by ChatGPT for difficult and medium problems is more likely to contain compilation and runtime errors”. The human coders who took the test scored an average of 66%.
For older problems, labeled “Bef.”, the percentage rises to 31%, which remains low.
The team has qualified the types of erroneous answers that ChatGPT provides. Often it is something as simple as the evaluation of a variable. A mistake that is difficult to imagine on the part of a beginner developer.

Example of erroneous code generated by ChatGPT. The program is supposed to classify boxes into categories according to their description. On line 12, the code decides that if a box is neither “bulky” nor “heavy”, it should be classified in the category “both” – when it should be “neither”. ShanghaiTech University
ChatGPT is more efficient with strongly typed languages
The researchers come to fascinating conclusions. First of all, they note that ChatGPT is facing new problems: “ChatGPT can have limitations when generating code for unfamiliar or new problems, even if the problems are easy to solve from a human point of view.”
But the programming language used has its importance: the technology works best with certain programming languages that are “strongly typed” or more “expressive”. “The probability that ChatGPT will generate functionally correct code is higher when using more strongly expressive languages (for example, Python3),” they write.
Another flaw is that ChatGPT can be convoluted, so its errors are more difficult to correct. “The code generation process of ChatGPT can be neglected”, they write, “and the generated code may not meet some of the detailed conditions described, which makes it difficult to successfully generate or correct (so that it is functional)”.
Regarding MITRE’s Common Vulnerabilities test, “the code generated by ChatGPT often has vulnerabilities, which constitutes a serious problem,” they write. Fortunately, they note that ChatGPT is able to fix many of these vulnerabilities in the following prompts when it receives more detailed information from the MITRE dataset.
The three studies therefore suggest that the use of generative AI for programming is still in its infancy. As Mr. Rao said, generative AI is useful for simple support tasks, when the programmer is in charge.
You May Also Like



More From Author

ServReality Brings Next-Gen Gaming Experiences to Apple Devices
January 23, 2026

The Top 25 Diamond and Pearl Pokémon
August 5, 2024


